À propos de moi
Je me présente

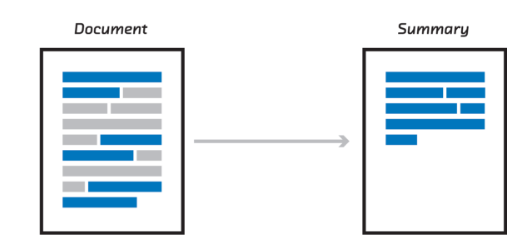
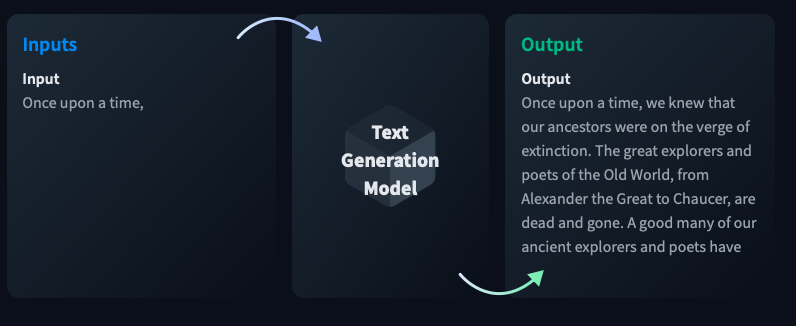
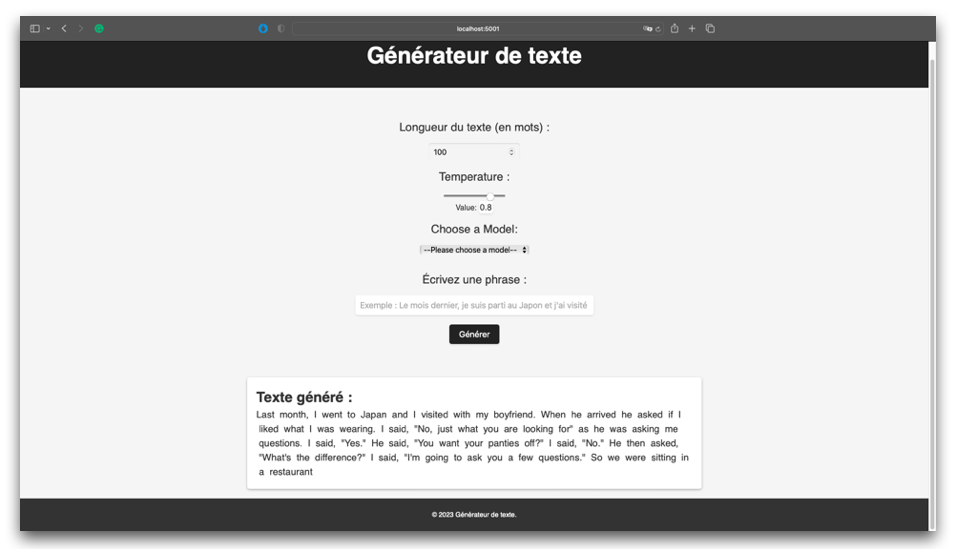
Jeune diplômé en ingénierie de l'IA avec une forte passion pour l'apprentissage automatique, la vision par ordinateur et la science des données. Motivé pour travailler sur des projets innovants et résoudre des problèmes complexes en utilisant des techniques d'IA avancées.
Profil
Jeune diplômé.
- Mon nom: Kenan Akira GONNOT
- Date de naissance: 28 avril 1999
-
Travail:
Data scientist junior,
MLOps engineer junior - Langages: • Français (Principal) • Japonais (Natif/Débutant) • Anglais (TOEIC - 840pts)
- Localisation: 75018 - PARIS FRANCE
- Site web: kenan.gonnot.net
- Email: kenan@gonnot.net

Compétences
Je suis un jeune data scientist avec une expérience dans la formation et l'optimisation des modèles NLP, LLM et des modèles CNN. Mon expertise réside dans le réglage fin des hyperparamètres afin d'obtenir une meilleure performance du modèle. Avec une perspective nouvelle et un engagement pour l'innovation, je suis prêt à avoir un impact significatif dans le domaine de la science des données.
-
60%Python
-
30%Javascript
-
60%Docker
-
35%Kubernetes
-
25%Tensorflow
-
20%PyTorch
-
25%Keras
-
20%Kubeflow